How to extract text from an pdf file using PdfBox and Itext Library
There are multiple use cases of the PDF extraction process such as analyzing resumes, extracting data from reports and uploading data in a database from PDF, and many more. To extract the text from the pdf in java you have to multiple way to achieve this PdfBox and Itext Library.
- PdfBox
- Free for commercial use
- Reliable and Robust
- Suitable for simple file creation and editing
- Lightweight and Optimized
- Ideal for extract the text, merge and splitting the pdf’s
- Itext
- Free for open source projects
- have rich set of features to enhance the user experience
- Supports sophisticated designs, layouts, and interactivity.
- heigh performance and better for complex and large pdf operation’s
- Best for enterprise-grade solutions needing advanced features like digital signatures and complex layouts.
these two library are commonly used with java 8 and above to text the text, create and modify the pdf or text file.
PDFBox
Apache PDFBox is an open-source Java library that can be use for multiple pdf operations like create, render, split, print, merge, after, verify, extract text and meta-data from pdf. We will create an api that will accept the file in the request payload. Add the bdfbox library in the pom.xml file.
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.9</version>
</dependency>Create a rest controller and paste the below code in the controller. Process: Read the input stream from the uploaded file then load the input stream by pdfDocument. Create a PDFTextStripper object from this object you can call the getText function to get the text from the PdfDocument object.
import java.io.IOException;
import java.io.InputStream;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import org.springframework.ws.server.endpoint.annotation.RequestPayload;
@RestController
@RequestMapping("api/v1")
public class TectController {
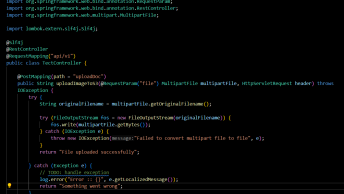
@PostMapping("/extractTextFromPdf")
public ResponseEntity<String> extractTextFromPdf(@RequestPayload MultipartFile pdfFile) {
try {
InputStream inputStream = pdfFile.getInputStream();
PDDocument document = PDDocument.load(inputStream);
PDFTextStripper stripper = new PDFTextStripper();
String extractedText = stripper.getText(document);
return ResponseEntity.ok(extractedText);
} catch (IOException e) {
e.printStackTrace();
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body("Failed to extract text from PDF.");
}
}
}

Itext
iText is an open-source Java library that can be used for multiple PDF operations like creating, reading, and manipulating the PDF. It extracts the data by line and removes the white space from the lines. Add the iText library to your pom.xml file
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.8</version>
</dependency>Now Create a RestController and paste the blow code.
import java.io.IOException;
import java.io.InputStream;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import org.springframework.ws.server.endpoint.annotation.RequestPayload;
import com.itextpdf.text.pdf.PdfReader;
import com.itextpdf.text.pdf.parser.PdfTextExtractor;
import com.itextpdf.text.pdf.parser.SimpleTextExtractionStrategy;
@RestController
@RequestMapping("api/v1")
public class TectController {
@PostMapping("/extractTextFromPdfByItext")
public ResponseEntity<String> extractTextFromPdfByItext(@RequestPayload MultipartFile pdfFile) {
try {
InputStream inputStream = pdfFile.getInputStream();
PdfReader pdfReader = new PdfReader(inputStream);
int noOfPages = pdfReader.getNumberOfPages();
StringBuilder sb = new StringBuilder();
for (int page = 1; page <= noOfPages; page++) {
sb.append(PdfTextExtractor.getTextFromPage(pdfReader, page, new SimpleTextExtractionStrategy()));
}
pdfReader.close();
return ResponseEntity.ok(sb.toString());
} catch (IOException e) {
e.printStackTrace();
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body("Failed to extract text from PDF.");
}
}
}
Postman testing of the above api